
1、starter命名规范
spring提供的starter:
spring-boot-starter-xxx-x.y.z.jar
spring-boot-xxx-autoconfigure-x.y.z.jar
第三方提供的starter:
xxx-spring-boot-starter-x.y.z.jar
2、动手制作自定义Spring-Boot-Starter的步骤
1、新建项目,引入依赖
引入spring-boot-starter、spring-boot-autoconfigure、第三方jar,如果需要生成配置元信息,加入spring-boot-configuration-processor
2、编写功能实现类
3、编写自动配置类
4、在resources/META-INF/spring.factories中配置自动装配类
5、打包
这里我们使用jsoup抓取网页信息为例,制作一个starter。
项目结构:
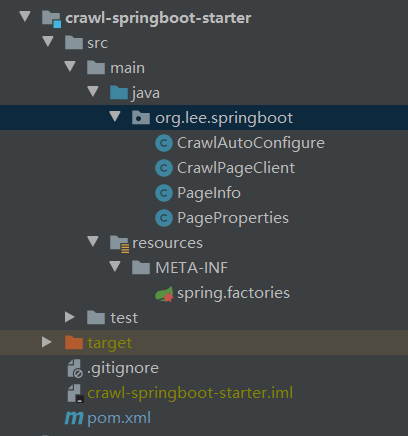
2.1、新建maven项目,引入依赖
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.1.3.RELEASE</version>
<relativePath />
</parent>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-autoconfigure</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-configuration-processor</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.11.3</version>
</dependency>
</dependencies>
2.2、编写功能实现类
编写实现抓取网页内容的类
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
public class CrawlPageClient {
private String pageUrl;
private CrawlPageClient() {
}
public CrawlPageClient(String pageUrl) {
this.pageUrl = pageUrl;
}
public static CrawlPageClient of(String pageUrl) {
return new CrawlPageClient(pageUrl);
}
public String getPageUrl() {
return pageUrl;
}
public PageInfo getPageInfo() {
PageInfo pageInfo = new PageInfo();
try {
Document doc = Jsoup.connect(pageUrl).get();
pageInfo.setUrl(pageUrl);
pageInfo.setTitle(doc.title());
pageInfo.setContent(doc.html());
return pageInfo;
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
}
网页信息类
public class PageInfo {
private String url;
private String title;
private String content;
public String getUrl() {
return url;
}
public void setUrl(String url) {
this.url = url;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
}
2.3、编写自动配置类
import org.springframework.boot.context.properties.EnableConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
@EnableConfigurationProperties( {PageProperties.class })
public class CrawlAutoConfigure {
@Bean
public CrawlPageClient create(PageProperties pageProperties) {
return CrawlPageClient.of(pageProperties.getPageUrl());
}
}
页面配置类,配置前缀:crawl
import org.springframework.boot.context.properties.ConfigurationProperties;
@ConfigurationProperties(prefix = PageProperties.CRAWL_PREFIX)
public class PageProperties {
public static final String CRAWL_PREFIX = "crawl";
private String pageUrl = "http://www.baidu.com";
public String getPageUrl() {
return pageUrl;
}
public void setPageUrl(String pageUrl) {
this.pageUrl = pageUrl;
}
}
默认抓取百度的页面内容
2.4、在resources/META-INF/spring.factories中配置自动装配类
org.springframework.boot.autoconfigure.EnableAutoConfiguration=\
cn.river.springboot.CrawlAutoConfigure
2.5、打包
打成jar包: crawl-spring-boot-starter-1.0.jar,maven依赖信息:
<dependency>
<groupId>cn.river.springboot</groupId>
<artifactId>crawl-spring-boot-starter</artifactId>
<version>1.0</version>
</dependency>
3、测试自定义starter
最后,新建测试项目测试自定义的starter。
引入依赖:
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.1.3.RELEASE</version>
<relativePath />
</parent>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!-- spring-boot crawl -->
<dependency>
<groupId>cn.river.springboot</groupId>
<artifactId>crawl-spring-boot-starter</artifactId>
<version>1.0</version>
</dependency>
</dependencies>
新建测试类:
import cn.river.springboot.CrawlPageClient;
import cn.river.springboot.PageInfo;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.ResponseBody;
import org.springframework.web.bind.annotation.RestController;
@RestController
@RequestMapping("crawl")
public class CrawlController {
@Autowired
private CrawlPageClient crawlPageClient;
@GetMapping("")
@ResponseBody
public PageInfo crawlPageInfo() {
StringBuilder pageBuilder = new StringBuilder();
pageBuilder.append("抓取到").append(crawlPageClient.getPageUrl())
.append("网页的信息<br/>").append(crawlPageClient.getPageInfo());
System.out.println(crawlPageClient.getPageInfo());
return crawlPageClient.getPageInfo();
}
}
运行程序,浏览器输入:http://127.0.0.1:8080/crawl
默认看到的是百度网页的信息:

我们在application.properties配置中加入以下配置:
crawl.page-url=https://www.csdn.net
抓取网页改成csdn的,再次运行程序,访问内容如下:

4、总结
本文简单介绍如何开发自定义的Spring-Boot-Starter,通过添加依赖自动完成功能导入,使用起来很方便,大家也可以自己动手实现自定义的starter。