
Python语音识别实战:FastAPI + Whisper ASR开发指南
1. 简介
本文介绍如何使用 FastAPI 框架结合 Whisper ASR(自动语音识别)技术构建一个完整的语音识别系统。该系统可以接收音频文件并将其转换为文本,支持多种音频格式和语言识别。
相关技术栈
FastAPI: 一个现代、快速(高性能)的 Python web 框架,基于标准 Python 类型提示。
Whisper: OpenAI 开源的通用语音识别模型,支持多种语言识别。
Pydub: 用于音频处理的 Python 库,支持多种音频格式转换。
Torch: Facebook 开源的机器学习框架,Whisper 模型依赖于此。
OpenCC: 用于中文繁简转换的开源项目。
Jinja2: Python 的模板引擎,用于构建 Web 界面。
Uvicorn: 用于运行 FastAPI 应用的 ASGI 服务器。
2. 安装配置
环境要求
Python 3.8+
CUDA(可选,用于 GPU 加速)
安装步骤
创建项目目录并进入:
mkdir fastapi_asr
cd fastapi_asr
创建项目文件,包括主应用文件、依赖列表和模板目录
安装依赖包:
pip install -r requirements.txtrequirements依赖项包括:
fastapi>=0.68.0
uvicorn>=0.15.0
openai-whisper>=20231106
torch>=1.13.0
pydub>=0.25.1
python-multipart>=0.0.5
jinja2>=3.0.0
安装系统依赖(针对音频处理):
在 Ubuntu/Debian 上:
sudo apt update
sudo apt install ffmpeg
在 CentOS/RHEL 上:
sudo yum install epel-release
sudo yum install ffmpeg
在 macOS 上:
brew install ffmpeg
下载 Whisper 模型:
第一次运行应用时会自动下载模型,也可以手动下载:
# 进入 Python 环境
python -c "import whisper; whisper.load_model('base')"
3. 代码实战
项目结构
fastapi_asr/
├── fastapi-asr.py # 主应用文件
├── requirements.txt # 依赖列表
├── templates/
│ └── asr.html # Web界面模板
├── test.wav # 测试音频文件
└── test_api.py # API测试脚本
核心代码
应用初始化
from fastapi import FastAPI, UploadFile, File, Query, HTTPException, Request
from fastapi.responses import JSONResponse, HTMLResponse
from fastapi.templating import Jinja2Templates
from pydub import AudioSegment
import io
import whisper
import torch
import os
import numpy as np
import opencc
# 初始化 FastAPI 应用
app = FastAPI(
title="开源音频转文字(ASR)接口",
description="支持 MP3/WAV 等格式,识别英语/中文",
version="1.0"
)
# 设置模板
templates = Jinja2Templates(directory="templates")
# 初始化繁简转换器
cc = opencc.OpenCC('t2s') # 繁体到简体
模型加载
def load_asr_model(model_size: str = "base") -> whisper.Whisper:
"""加载 Whisper 模型,自动适配 CPU/GPU"""
try:
# 检查 GPU 是否可用(有 GPU 自动使用,无则用 CPU)
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"使用设备:{device},加载模型:whisper-{model_size}")
model = whisper.load_model(model_size, device=device)
return model
except Exception as e:
raise HTTPException(status_code=500, detail=f"模型加载失败:{str(e)}")
# 预加载模型(启动服务时加载,首次请求无需等待)
ASR_MODEL = load_asr_model(model_size="base") # 可改为 "small" 提升准确率
音频处理
def convert_audio_to_wav(audio_io: io.BytesIO, input_format: str) -> np.ndarray:
"""将任意支持的音频格式转换为 Whisper 兼容的 WAV 格式 numpy 数组"""
try:
# 尝试多种方式读取音频文件
audio = None
# 方法1: 使用指定格式读取
if input_format:
try:
audio_io.seek(0)
audio = AudioSegment.from_file(audio_io, format=input_format)
except:
pass
# 方法2: 自动检测格式
if audio is None:
try:
audio_io.seek(0)
audio = AudioSegment.from_file(audio_io)
except:
pass
# 方法3: 尝试作为 WAV 文件读取
if audio is None:
try:
audio_io.seek(0)
audio = AudioSegment.from_wav(audio_io)
except:
pass
# 如果所有方法都失败了,则抛出异常
if audio is None:
raise Exception("无法解码音频文件")
# 转换为:16kHz 采样率、单声道、16 位深度(Whisper 要求)
wav_audio = audio.set_frame_rate(16000).set_channels(1).set_sample_width(2)
# 转换为 numpy 数组
samples = np.array(wav_audio.get_array_of_samples(), dtype=np.float32)
# 归一化到 [-1, 1]
samples = samples / (1 << 15)
return samples
except Exception as e:
raise HTTPException(status_code=400, detail=f"音频格式转换失败:{str(e)}")
API 接口实现
# 接口:单文件音频转文字(POST 请求,支持大文件上传)
@app.post("/asr/speech-to-text", summary="音频转文字(单文件)")
async def speech_to_text(
file: UploadFile = File(..., description=f"音频文件,支持格式:{SUPPORTED_FORMATS},建议文件大小≤100MB"),
language: str = Query("auto", description=f"识别语言:{SUPPORTED_LANGUAGES}(auto=自动检测)"),
model_size: str = Query("base", description="模型大小:base(快)/ small(准),默认 base"),
temperature: float = Query(0.0, ge=0.0, le=1.0, description="识别温度(0.0=更精确,1.0=更多样)")
):
# 1. 校验输入
if not file.filename:
raise HTTPException(status_code=400, detail="音频文件不能为空")
# 校验文件格式
file_ext = file.filename.split(".")[-1].lower()
if file_ext not in SUPPORTED_FORMATS:
raise HTTPException(status_code=400, detail=f"不支持的音频格式:{file_ext},仅支持:{SUPPORTED_FORMATS}")
if language not in SUPPORTED_LANGUAGES:
raise HTTPException(status_code=400, detail=f"不支持的语言:{language},仅支持:{SUPPORTED_LANGUAGES}")
# 校验文件大小(可选,避免超大文件占用资源)
file_size = await file.read(1) # 读取 1 字节获取文件大小(FastAPI 特性)
await file.seek(0) # 重置文件指针
if file.size > 100 * 1024 * 1024: # 100MB 限制
raise HTTPException(status_code=400, detail="文件大小超过限制(最大 100MB)")
try:
# 2. 读取音频文件到 BytesIO
audio_bytes = await file.read()
audio_io = io.BytesIO(audio_bytes)
audio_io.seek(0)
# 3. 转换为 Whisper 兼容的 WAV 格式
wav_io = convert_audio_to_wav(audio_io, file_ext)
# 4. 加载 WAV 音频并识别
result = ASR_MODEL.transcribe(
wav_io,
language=language if language != "auto" else None, # auto 时传 None
temperature=temperature,
fp16=False # CPU 必须设为 False,GPU 可设为 True 提速
)
# 5. 如果是中文,进行繁简转换
recognized_text = result["text"].strip()
if result["language"] == "zh":
recognized_text = cc.convert(recognized_text)
# 6. 整理返回结果
return JSONResponse({
"status": "success",
"data": {
"text": recognized_text, # 识别后的文字(已转换为简体)
"language": result["language"], # 实际识别的语言
"segments": result["segments"], # 分段识别结果(含时间戳)
"file_info": {
"filename": file.filename,
"format": file_ext,
"size_mb": round(len(audio_bytes) / 1024 / 1024, 2)
}
}
})
except Exception as e:
raise HTTPException(status_code=500, detail=f"音频识别失败:{str(e)}")
Web 界面
通过 Jinja2 模板引擎提供了一个友好的 Web 界面,用户可以通过浏览器上传音频文件进行识别:
# 主页路由 - 返回Web界面
@app.get("/", response_class=HTMLResponse)
async def root(request: Request):
"""API根路径 - 返回Web界面"""
return templates.TemplateResponse("asr.html", {"request": request})
模板代码 (asr.html)
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>语音识别服务</title>
<style>
body {
font-family: 'Segoe UI', Tahoma, Geneva, Verdana, sans-serif;
max-width: 800px;
margin: 0 auto;
padding: 20px;
background-color: #f5f5f5;
}
.container {
background-color: white;
padding: 30px;
border-radius: 10px;
box-shadow: 0 4px 6px rgba(0, 0, 0, 0.1);
}
h1 {
color: #333;
text-align: center;
margin-bottom: 30px;
}
.form-group {
margin-bottom: 20px;
}
label {
display: block;
margin-bottom: 5px;
font-weight: bold;
color: #555;
}
input, select {
width: 100%;
padding: 12px;
border: 1px solid #ddd;
border-radius: 5px;
font-size: 16px;
margin-bottom: 10px;
}
button {
background-color: #4CAF50;
color: white;
padding: 12px 24px;
border: none;
border-radius: 5px;
cursor: pointer;
font-size: 16px;
width: 100%;
transition: background-color 0.3s;
margin-bottom: 10px;
}
button:hover {
background-color: #45a049;
}
button:disabled {
background-color: #cccccc;
cursor: not-allowed;
}
.record-button {
background-color: #f44336;
}
.record-button.recording {
background-color: #ff9800;
animation: pulse 1s infinite;
}
@keyframes pulse {
0% { opacity: 1; }
50% { opacity: 0.7; }
100% { opacity: 1; }
}
.result-container {
margin-top: 20px;
padding: 15px;
border: 1px solid #ddd;
border-radius: 5px;
background-color: #f9f9f9;
display: none;
}
.status {
text-align: center;
margin: 15px 0;
min-height: 20px;
}
.loading {
color: #ff9800;
}
.success {
color: #4CAF50;
}
.error {
color: #f44336;
}
.hidden {
display: none;
}
.file-info {
background-color: #e3f2fd;
border-left: 4px solid #2196F3;
padding: 10px;
margin-bottom: 15px;
border-radius: 4px;
}
textarea {
width: 100%;
min-height: 100px;
padding: 12px;
border: 1px solid #ddd;
border-radius: 5px;
font-size: 16px;
resize: vertical;
}
.recording-info {
text-align: center;
margin: 10px 0;
font-weight: bold;
}
.tab-container {
display: flex;
margin-bottom: 20px;
}
.tab {
flex: 1;
padding: 12px;
text-align: center;
background-color: #f0f0f0;
cursor: pointer;
border: 1px solid #ddd;
}
.tab:first-child {
border-radius: 5px 0 0 5px;
}
.tab:last-child {
border-radius: 0 5px 5px 0;
}
.tab.active {
background-color: #4CAF50;
color: white;
}
.tab-content {
display: none;
}
.tab-content.active {
display: block;
}
</style>
</head>
<body>
<div class="container">
<h1>语音识别服务</h1>
<!-- 标签页 -->
<div class="tab-container">
<div class="tab active" onclick="switchTab('file')">上传文件</div>
<div class="tab" onclick="switchTab('record')">麦克风录音</div>
</div>
<!-- 上传文件标签页 -->
<div id="file-tab" class="tab-content active">
<form id="asrForm" enctype="multipart/form-data">
<div class="form-group">
<label for="audioFile">选择音频文件:</label>
<input type="file" id="audioFile" name="file" accept=".mp3,.wav,.ogg,.flac,.m4a" required>
<div class="file-info">
<strong>支持格式:</strong> MP3, WAV, OGG, FLAC, M4A<br>
<strong>文件大小:</strong> 最大100MB
</div>
</div>
<div class="form-group">
<label for="language">识别语言:</label>
<select id="language" name="language">
<option value="auto">自动检测</option>
<option value="zh">中文</option>
<option value="en">英文</option>
</select>
</div>
<div class="form-group">
<label for="modelSize">模型大小:</label>
<select id="modelSize" name="model_size">
<option value="base">基础模型 (较快)</option>
<option value="small">小型模型 (较准确)</option>
</select>
</div>
<div class="form-group">
<label for="temperature">识别温度: <span id="temperatureValue">0.0</span></label>
<input type="range" id="temperature" name="temperature" min="0" max="1" step="0.1" value="0">
</div>
<button type="submit" id="recognizeButton">开始识别</button>
</form>
</div>
<!-- 麦克风录音标签页 -->
<div id="record-tab" class="tab-content">
<div class="form-group">
<label>录音控制:</label>
<button id="recordButton" class="record-button" onclick="toggleRecording()">开始录音</button>
<div class="recording-info" id="recordingInfo"></div>
<div class="file-info">
<strong>注意:</strong> 录音功能需要浏览器支持 getUserMedia API,并且需要 HTTPS 或 localhost 环境。<br>
<strong>录音格式:</strong> WAV (44.1kHz, 16-bit, mono)
</div>
</div>
<div class="form-group">
<label for="recordLanguage">识别语言:</label>
<select id="recordLanguage">
<option value="auto">自动检测</option>
<option value="zh">中文</option>
<option value="en">英文</option>
</select>
</div>
<div class="form-group">
<label for="recordModelSize">模型大小:</label>
<select id="recordModelSize">
<option value="base">基础模型 (较快)</option>
<option value="small">小型模型 (较准确)</option>
</select>
</div>
<div class="form-group">
<label for="recordTemperature">识别温度: <span id="recordTemperatureValue">0.0</span></label>
<input type="range" id="recordTemperature" min="0" max="1" step="0.1" value="0">
</div>
<button id="uploadRecordButton" onclick="uploadRecording()" disabled>上传并识别</button>
</div>
<div class="status" id="status"></div>
<div class="result-container" id="resultContainer">
<h3>识别结果</h3>
<div class="form-group">
<label>识别文本:</label>
<textarea id="resultText" readonly></textarea>
</div>
<div class="form-group">
<label>识别语言:</label>
<input type="text" id="resultLanguage" readonly>
</div>
<div class="form-group">
<label>文件信息:</label>
<input type="text" id="fileInfo" readonly>
</div>
</div>
</div>
<script>
// 全局变量
let mediaRecorder;
let audioChunks = [];
let recordingStartTime;
// 更新温度值显示
document.getElementById('temperature').addEventListener('input', function() {
document.getElementById('temperatureValue').textContent = this.value;
});
document.getElementById('recordTemperature').addEventListener('input', function() {
document.getElementById('recordTemperatureValue').textContent = this.value;
});
// 表单提交处理
document.getElementById('asrForm').addEventListener('submit', function(e) {
e.preventDefault();
const fileInput = document.getElementById('audioFile');
const file = fileInput.files[0];
if (!file) {
showStatus('请选择音频文件', 'error');
return;
}
// 检查文件大小
if (file.size > 100 * 1024 * 1024) { // 100MB
showStatus('文件大小超过限制(最大100MB)', 'error');
return;
}
// 构造FormData
const formData = new FormData();
formData.append('file', file);
formData.append('language', document.getElementById('language').value);
formData.append('model_size', document.getElementById('modelSize').value);
formData.append('temperature', document.getElementById('temperature').value);
// 禁用按钮并显示加载状态
const recognizeButton = document.getElementById('recognizeButton');
recognizeButton.disabled = true;
showStatus('正在识别音频...', 'loading');
// 隐藏之前的结果
document.getElementById('resultContainer').style.display = 'none';
// 发送请求到ASR接口
fetch('/asr/speech-to-text', {
method: 'POST',
body: formData
})
.then(response => {
if (!response.ok) {
return response.text().then(text => {
throw new Error(`HTTP ${response.status}: ${text}`);
});
}
return response.json();
})
.then(data => {
if (data.status === 'success') {
// 显示结果
document.getElementById('resultText').value = data.data.text;
document.getElementById('resultLanguage').value = data.data.language;
document.getElementById('fileInfo').value =
`${data.data.file_info.filename} (${data.data.file_info.format}, ${data.data.file_info.size_mb} MB)`;
document.getElementById('resultContainer').style.display = 'block';
showStatus('识别成功!', 'success');
} else {
throw new Error(data.detail || '识别失败');
}
})
.catch(error => {
console.error('Error:', error);
showStatus('识别出错: ' + error.message, 'error');
})
.finally(() => {
recognizeButton.disabled = false;
});
});
// 切换标签页
function switchTab(tabName) {
// 更新标签页按钮样式
document.querySelectorAll('.tab').forEach(tab => {
tab.classList.remove('active');
});
// 显示对应的内容
document.querySelectorAll('.tab-content').forEach(content => {
content.classList.remove('active');
});
if (tabName === 'file') {
document.querySelector('.tab:nth-child(1)').classList.add('active');
document.getElementById('file-tab').classList.add('active');
} else {
document.querySelector('.tab:nth-child(2)').classList.add('active');
document.getElementById('record-tab').classList.add('active');
}
}
// 切换录音状态
function toggleRecording() {
const recordButton = document.getElementById('recordButton');
if (recordButton.textContent.includes('开始录音')) {
startRecording();
} else {
stopRecording();
}
}
// 开始录音
async function startRecording() {
try {
const stream = await navigator.mediaDevices.getUserMedia({ audio: true });
mediaRecorder = new MediaRecorder(stream);
audioChunks = [];
mediaRecorder.ondataavailable = event => {
audioChunks.push(event.data);
};
mediaRecorder.onstop = () => {
// 停止所有音频轨道
stream.getTracks().forEach(track => track.stop());
};
mediaRecorder.start();
recordingStartTime = new Date();
updateRecordingTimer();
// 更新UI
const recordButton = document.getElementById('recordButton');
recordButton.textContent = '停止录音';
recordButton.classList.add('recording');
document.getElementById('recordingInfo').textContent = '录音中... 00:00';
showStatus('开始录音...', 'loading');
} catch (error) {
console.error('录音错误:', error);
showStatus('无法访问麦克风: ' + error.message, 'error');
}
}
// 更新录音计时器
function updateRecordingTimer() {
if (mediaRecorder && mediaRecorder.state === 'recording') {
const elapsedTime = Math.floor((new Date() - recordingStartTime) / 1000);
const minutes = Math.floor(elapsedTime / 60).toString().padStart(2, '0');
const seconds = (elapsedTime % 60).toString().padStart(2, '0');
document.getElementById('recordingInfo').textContent = `录音中... ${minutes}:${seconds}`;
setTimeout(updateRecordingTimer, 1000);
}
}
// 停止录音
function stopRecording() {
if (mediaRecorder && mediaRecorder.state === 'recording') {
mediaRecorder.stop();
// 更新UI
const recordButton = document.getElementById('recordButton');
recordButton.textContent = '开始录音';
recordButton.classList.remove('recording');
document.getElementById('recordingInfo').textContent = '录音已完成';
document.getElementById('uploadRecordButton').disabled = false;
showStatus('录音完成,点击"上传并识别"按钮进行识别', 'success');
}
}
// 上传录音
function uploadRecording() {
if (audioChunks.length === 0) {
showStatus('没有录音数据', 'error');
return;
}
// 创建 Blob 对象
const audioBlob = new Blob(audioChunks, { type: 'audio/wav' });
// 创建文件名
const timestamp = new Date().toISOString().replace(/[:.]/g, '-');
const filename = `recording-${timestamp}.wav`;
// 构造FormData
const formData = new FormData();
formData.append('file', audioBlob, filename);
formData.append('language', document.getElementById('recordLanguage').value);
formData.append('model_size', document.getElementById('recordModelSize').value);
formData.append('temperature', document.getElementById('recordTemperature').value);
// 禁用按钮并显示加载状态
const uploadRecordButton = document.getElementById('uploadRecordButton');
uploadRecordButton.disabled = true;
showStatus('正在识别录音...', 'loading');
// 隐藏之前的结果
document.getElementById('resultContainer').style.display = 'none';
// 发送请求到ASR接口
fetch('/asr/speech-to-text', {
method: 'POST',
body: formData
})
.then(response => {
if (!response.ok) {
return response.text().then(text => {
throw new Error(`HTTP ${response.status}: ${text}`);
});
}
return response.json();
})
.then(data => {
if (data.status === 'success') {
// 显示结果
document.getElementById('resultText').value = data.data.text;
document.getElementById('resultLanguage').value = data.data.language;
document.getElementById('fileInfo').value =
`${filename} (WAV, ${(audioBlob.size / 1024 / 1024).toFixed(2)} MB)`;
document.getElementById('resultContainer').style.display = 'block';
showStatus('识别成功!', 'success');
} else {
throw new Error(data.detail || '识别失败');
}
})
.catch(error => {
console.error('Error:', error);
showStatus('识别出错: ' + error.message, 'error');
})
.finally(() => {
uploadRecordButton.disabled = false;
});
}
function showStatus(message, type) {
const statusElement = document.getElementById('status');
statusElement.textContent = message;
statusElement.className = 'status ' + type;
}
</script>
</body>
</html>
4. 测试运行
启动服务
python fastapi-asr.py
或者使用 uvicorn 命令:
uvicorn fastapi-asr:app --host 127.0.0.1 --port 8000 --reload
启动后,可以通过以下地址访问:
Web 界面: http://127.0.0.1:8000
API 文档: http://127.0.0.1:8000/docs
API 状态: http://127.0.0.1:8000/asr/status
访问web界面效果如下:
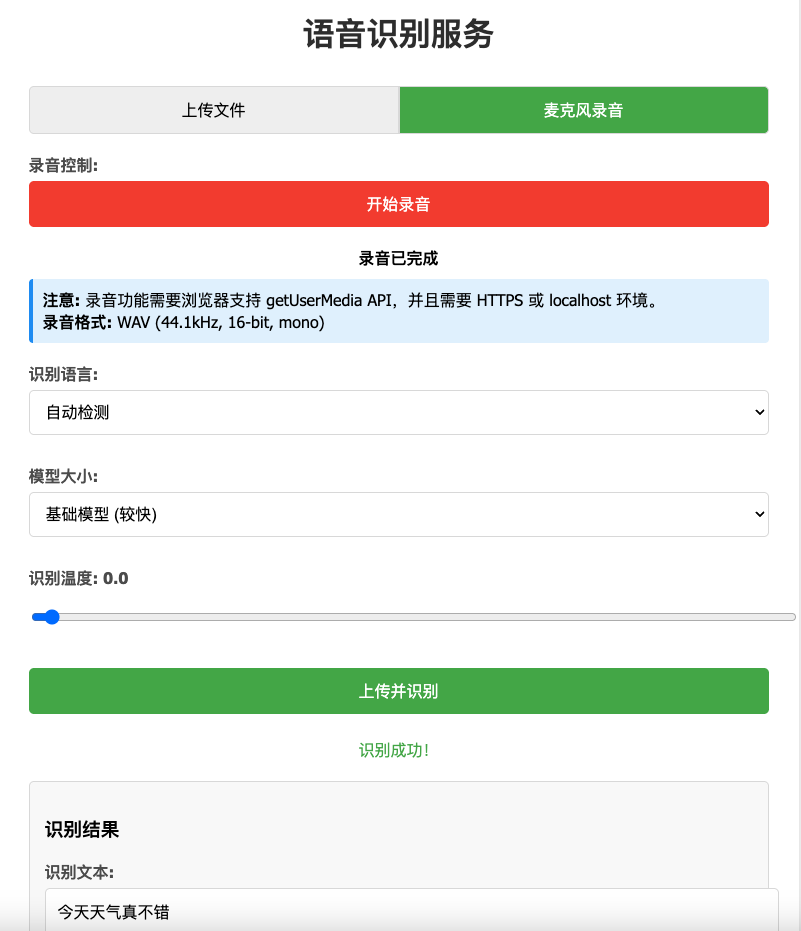
API 测试
使用提供的测试脚本进行测试:
import requests
url = "http://127.0.0.1:8000/asr/speech-to-text"
files = {
"file": ("test.wav", open("test.wav", "rb"), "audio/wav")
}
params = {
"language": "zh", # 指定中文识别
"model_size": "base"
}
response = requests.post(url, files=files, params=params)
if response.status_code == 200:
print("识别成功:", response.json()["data"]["text"])
else:
print("识别失败:", response.text)
5. 常见问题及解决方案
问题1: 模型加载缓慢或失败
原因: 网络问题导致模型下载失败或速度慢。
解决方案:
手动下载模型并放置在正确位置
使用代理或镜像源加速下载
更换较小的模型(如 base 替代 large)
问题2: 音频格式不支持
原因: 系统缺少必要的编解码器或 FFmpeg 未正确安装。
解决方案:
确保已安装 FFmpeg 并添加到 PATH
安装额外的音频编解码器
检查音频文件是否损坏
问题3: 内存不足
原因: 大型模型或长时间音频文件导致内存溢出。
解决方案:
使用较小的模型(如 base 而非 large)
限制上传文件大小
增加系统交换空间
使用 GPU 加速减少内存占用
问题4: 中文识别效果不佳
原因: 模型对特定方言或口音适应性差。
解决方案:
尝试不同大小的模型
明确指定语言为 “zh” 而非 “auto”
使用专业训练的中文语音识别模型
对音频进行预处理以提高质量
问题5: GPU 未被利用
原因: CUDA 驱动或 PyTorch GPU 版本未正确安装。
解决方案:
检查 CUDA 驱动版本是否匹配
安装支持 CUDA 的 PyTorch 版本
验证 GPU 是否被 PyTorch 识别:
import torch
print(torch.cuda.is_available())
通过以上指南,您可以成功搭建并运行一个基于 FastAPI 和 Whisper 的语音识别系统,满足各种语音转文字的需求。